🧑🏽🔬 P-values & Hypothesis Tests
Exploring the hbr_maples dataset!

stem_length: a number denoting the height of the seedling in millimeters
stem_dry_mass: a number denoting the dry mass of the stem in grams

What condition do we need to be worried about?
The final product
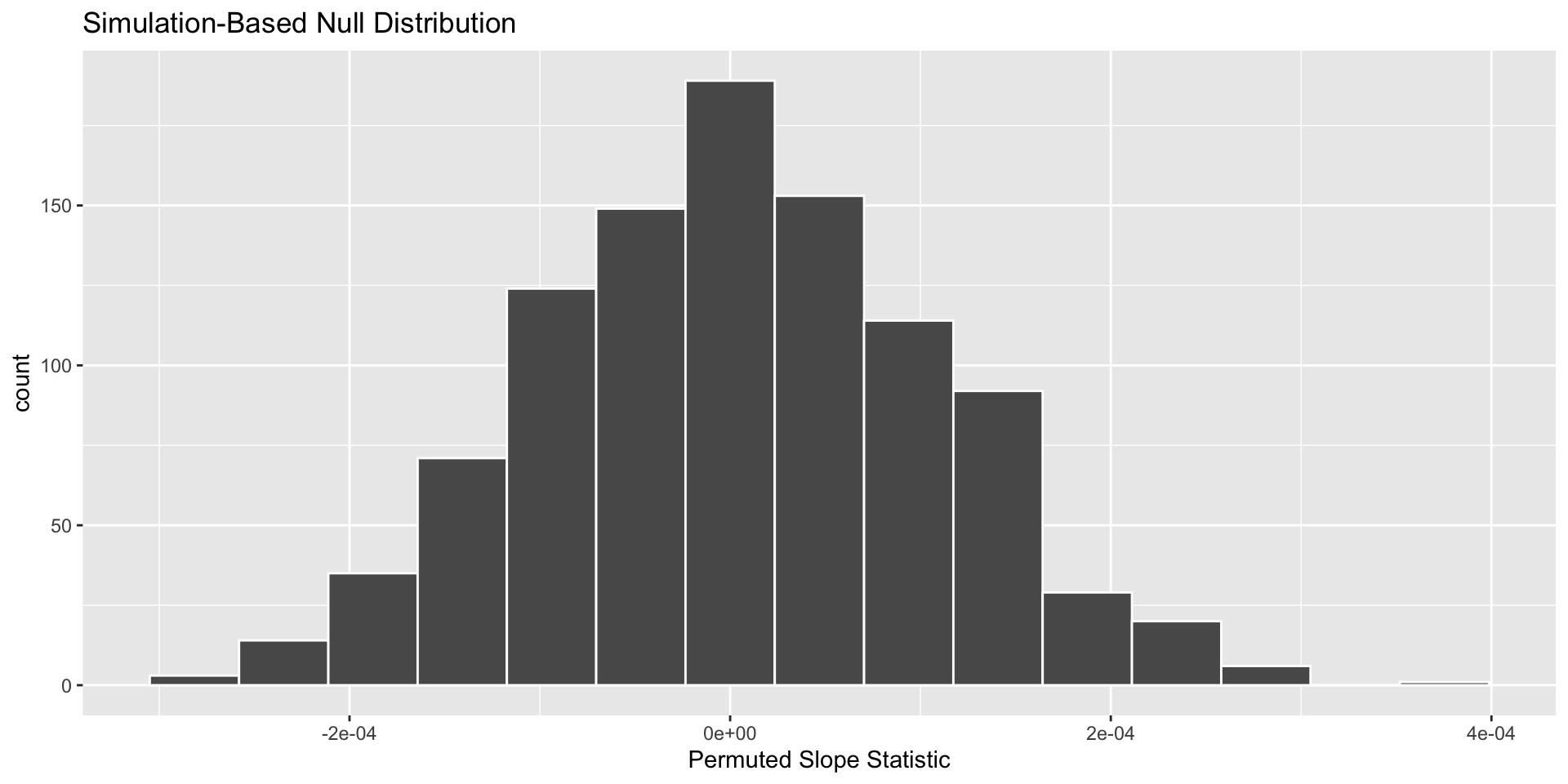
Is our observed statistic unlikely if the null hypothesis was true?
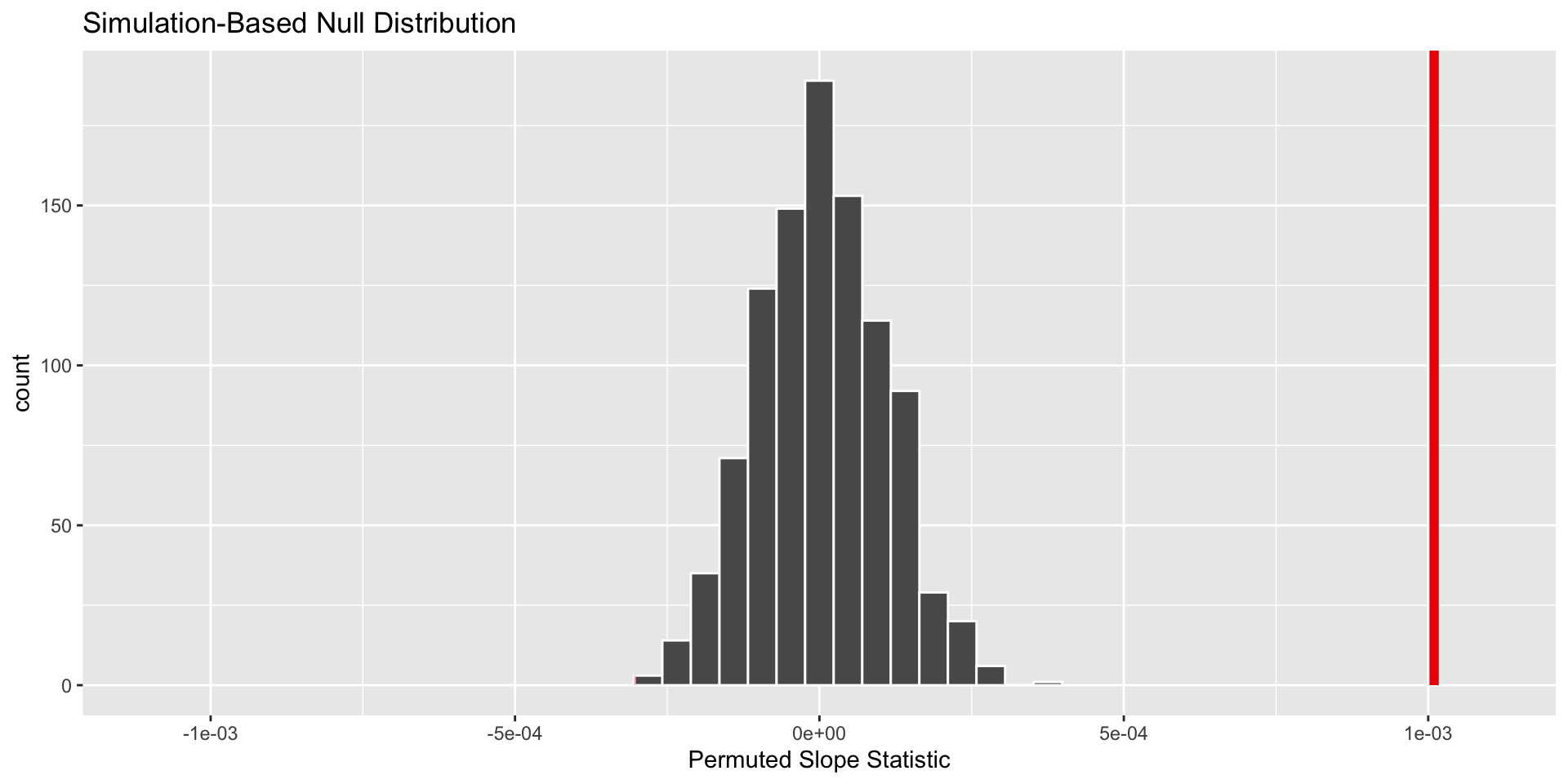
Two-sided Alternative
If our alternative hypothesis is two-sided, what is missing from the plot?
Today’s Data
“One of the best-known patterns in biogeography is Bergmann’s rule. It predicts that organisms at higher latitudes are larger than ones at lower latitudes. Many organisms follow Bergmann’s rule, including insects, birds, snakes, marine invertebrates, and > terrestrial and marine mammals. What drives Bergmann’s rule? Bergmann originally hypothesized that the organisms he studied, birds, were larger in the colder, higher latitudes due to heat-conservation. But the heat-conservation hypothesis relies on internal regulation of body temperature and therefore does not apply to ectotherms, some of which also follow Bergmann’s rule.”
