military_clean %>%
filter(
if_all(.cols = -Country,
.fns = ~ is.na(.x)
),
!is.na(Country)
) %>%
pull(Country)Extending Joins, Factors, Clean Variable Names
Practice Activity 4

janitor Package

Image by Allison Horst
Lifceycle Stages
As packages get updated, the functions and function arguments included in those packages will change.
- The accepted syntax for a function may change.
- A function/functionality may disappear.
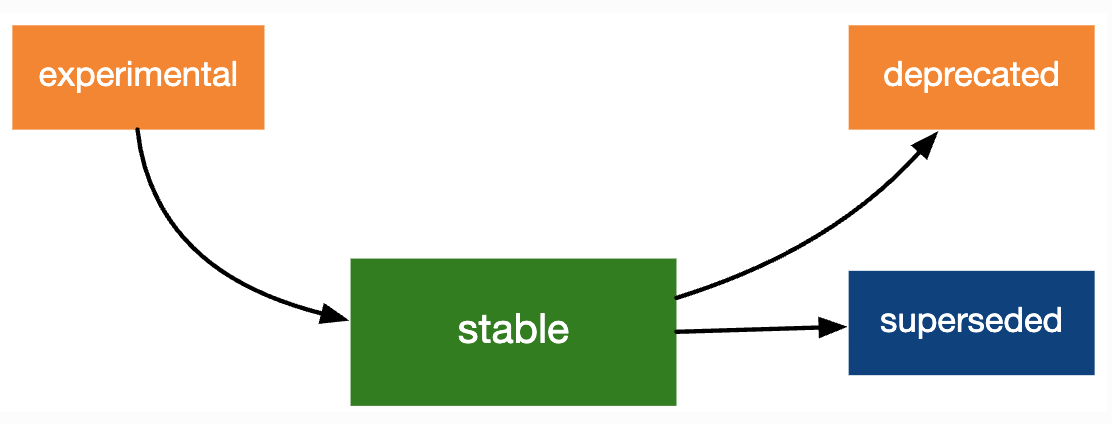
Learn more about lifecycle stages of packages, functions, function arguments in R.
Lifceycle Stages

IMDb Movies Data

How can we find each director’s active years?
Joining Multiple Data Sets

movies_directors |>
inner_join(directors,
by = join_by(director_id == id)
)| director_id | movie_id | first_name | last_name |
|---|---|---|---|
| 429 | 300229 | Andrew | Adamson |
| 2931 | 254943 | Darren | Aronofsky |
| 9247 | 124110 | Zach | Braff |
| 11652 | 10920 | James (I) | Cameron |
| 11652 | 333856 | James (I) | Cameron |
| 14927 | 192017 | Ron | Clements |
| 15092 | 109093 | Ethan | Coen |
| 15092 | 237431 | Ethan | Coen |
| 15093 | 109093 | Joel | Coen |
| 15093 | 237431 | Joel | Coen |
| 15901 | 130128 | Francis Ford | Coppola |
| 15906 | 194874 | Sofia | Coppola |
| 16816 | 350424 | Cameron | Crowe |
| 17810 | 297838 | Frank | Darabont |
| 22104 | 224842 | Clint | Eastwood |
| 24758 | 112290 | David | Fincher |
| 28395 | 46169 | Mel (I) | Gibson |
| 35573 | 18979 | Ron | Howard |
| 35838 | 257264 | John (I) | Hughes |
| 37872 | 300229 | Vicky | Jenson |
| 38746 | 238695 | Mike (I) | Judge |
| 41975 | 314965 | David | Koepp |
| 44291 | 17173 | John (I) | Landis |
| 46315 | 344203 | Jay | Levey |
| 48115 | 313459 | George | Lucas |
| 56332 | 192017 | John | Musker |
| 58201 | 30959 | Christopher | Nolan |
| 58201 | 210511 | Christopher | Nolan |
| 65940 | 111813 | Rob | Reiner |
| 66849 | 306032 | Guy | Ritchie |
| 68161 | 116907 | Herbert (I) | Ross |
| 74758 | 238072 | Steven | Soderbergh |
| 76524 | 167324 | Oliver (I) | Stone |
| 78273 | 176711 | Quentin | Tarantino |
| 78273 | 176712 | Quentin | Tarantino |
| 78273 | 267038 | Quentin | Tarantino |
| 78273 | 276217 | Quentin | Tarantino |
| 82525 | 147603 | Paul (I) | Verhoeven |
| 83616 | 207992 | Andy | Wachowski |
| 83617 | 207992 | Larry | Wachowski |
| 88802 | 256630 | Unknown | Director |
movies_directors |>
inner_join(directors,
by = join_by(director_id == id)
) |>
inner_join(movies,
by = join_by(movie_id == id)
) |>
rename(movie_name = name)| director_id | movie_id | first_name | last_name | movie_name | year | rank |
|---|---|---|---|---|---|---|
| 429 | 300229 | Andrew | Adamson | Shrek | 2001 | 8.1 |
| 2931 | 254943 | Darren | Aronofsky | Pi | 1998 | 7.5 |
| 9247 | 124110 | Zach | Braff | Garden State | 2004 | 8.3 |
| 11652 | 10920 | James (I) | Cameron | Aliens | 1986 | 8.2 |
| 11652 | 333856 | James (I) | Cameron | Titanic | 1997 | 6.9 |
| 14927 | 192017 | Ron | Clements | Little Mermaid, The | 1989 | 7.3 |
| 15092 | 109093 | Ethan | Coen | Fargo | 1996 | 8.2 |
| 15092 | 237431 | Ethan | Coen | O Brother, Where Art Thou? | 2000 | 7.8 |
| 15093 | 109093 | Joel | Coen | Fargo | 1996 | 8.2 |
| 15093 | 237431 | Joel | Coen | O Brother, Where Art Thou? | 2000 | 7.8 |
| 15901 | 130128 | Francis Ford | Coppola | Godfather, The | 1972 | 9.0 |
| 15906 | 194874 | Sofia | Coppola | Lost in Translation | 2003 | 8.0 |
| 16816 | 350424 | Cameron | Crowe | Vanilla Sky | 2001 | 6.9 |
| 17810 | 297838 | Frank | Darabont | Shawshank Redemption, The | 1994 | 9.0 |
| 22104 | 224842 | Clint | Eastwood | Mystic River | 2003 | 8.1 |
| 24758 | 112290 | David | Fincher | Fight Club | 1999 | 8.5 |
| 28395 | 46169 | Mel (I) | Gibson | Braveheart | 1995 | 8.3 |
| 35573 | 18979 | Ron | Howard | Apollo 13 | 1995 | 7.5 |
| 35838 | 257264 | John (I) | Hughes | Planes, Trains & Automobiles | 1987 | 7.2 |
| 37872 | 300229 | Vicky | Jenson | Shrek | 2001 | 8.1 |
| 38746 | 238695 | Mike (I) | Judge | Office Space | 1999 | 7.6 |
| 41975 | 314965 | David | Koepp | Stir of Echoes | 1999 | 7.0 |
| 44291 | 17173 | John (I) | Landis | Animal House | 1978 | 7.5 |
| 46315 | 344203 | Jay | Levey | UHF | 1989 | 6.6 |
| 48115 | 313459 | George | Lucas | Star Wars | 1977 | 8.8 |
| 56332 | 192017 | John | Musker | Little Mermaid, The | 1989 | 7.3 |
| 58201 | 30959 | Christopher | Nolan | Batman Begins | 2005 | NA |
| 58201 | 210511 | Christopher | Nolan | Memento | 2000 | 8.7 |
| 65940 | 111813 | Rob | Reiner | Few Good Men, A | 1992 | 7.5 |
| 66849 | 306032 | Guy | Ritchie | Snatch. | 2000 | 7.9 |
| 68161 | 116907 | Herbert (I) | Ross | Footloose | 1984 | 5.8 |
| 74758 | 238072 | Steven | Soderbergh | Ocean's Eleven | 2001 | 7.5 |
| 76524 | 167324 | Oliver (I) | Stone | JFK | 1991 | 7.8 |
| 78273 | 176711 | Quentin | Tarantino | Kill Bill: Vol. 1 | 2003 | 8.4 |
| 78273 | 176712 | Quentin | Tarantino | Kill Bill: Vol. 2 | 2004 | 8.2 |
| 78273 | 267038 | Quentin | Tarantino | Pulp Fiction | 1994 | 8.7 |
| 78273 | 276217 | Quentin | Tarantino | Reservoir Dogs | 1992 | 8.3 |
| 82525 | 147603 | Paul (I) | Verhoeven | Hollow Man | 2000 | 5.3 |
| 83616 | 207992 | Andy | Wachowski | Matrix, The | 1999 | 8.5 |
| 83617 | 207992 | Larry | Wachowski | Matrix, The | 1999 | 8.5 |
| 88802 | 256630 | Unknown | Director | Pirates of the Caribbean | 2003 | NA |
forcats
We use this package to…
turn character variables into factors.
make factors by discretizing numeric variables.
rename or reorder the levels of an existing factor.

forcats loads with tidyverse!
The packages forcats (“for categoricals”) helps wrangle categorical variables.
Re-ordering Factors in ggplot2
The bars follow the default factor levels.

We can order factor levels to order the bar plot.
full_eras |>
mutate(Album = fct(Album,
levels = c("Fearless",
"Speak Now",
"Red",
"1989",
"Reputation",
"Lover",
"Folklore",
"Evermore",
"Midnights")
)
) |>
ggplot(mapping = aes(y = Album,
fill = Album)
) +
geom_bar() +
theme_minimal() +
theme(legend.position = "none") +
labs(x = "",
y = "",
title = "Number of Songs Played on the Eras Tour by Album")
Re-ordering Factors in ggplot2
The ridge plots follow the order of the factor levels.

Inside ggplot(), we can order factor levels by a summary value.

Re-ordering Factors in ggplot2
The legend follows the order of the factor levels.
full_eras |>
filter(!Album %in% c("1989","Fearless")) |>
group_by(Album, Single) |>
summarise(avg_len = mean(Length)) |>
ggplot(mapping = aes(x = Single,
y = avg_len,
color = Album)) +
geom_point(size = 1.5) +
geom_line() +
theme_minimal() +
scale_x_continuous(breaks = c(0,1),
labels = c("No", "Yes")
) +
labs(y = "",
title = "Are Taylor Swift's Singles Shorter?",
color = "Album")
Inside ggplot(), we can order factor levels by the \(y\) values associated with the largest \(x\) values.
full_eras |>
filter(!Album %in% c("1989","Fearless")) |>
group_by(Album, Single) |>
summarise(avg_len = mean(Length)) |>
ggplot(mapping = aes(x = Single,
y = avg_len,
color = fct_reorder2(.f = Album,
.x = Single,
.y = avg_len)
)
) +
geom_point(size = 1.5) +
geom_line() +
theme_minimal() +
scale_x_continuous(breaks = c(0,1),
labels = c("No", "Yes")
) +
labs(y = "",
title = "Are Taylor Swift's Singles Shorter?",
color = "Album")
Lab 4: Childcare Costs in California