library(liver)
data(cereal)
head(cereal)Data Joins + Pivots
Tidy Data
Tidy data…
- is rectangular.
- has observations as rows and variables as columns.
- has different formats for different tasks.

Creating Tidy Data
We may need to transform our data to turn it into the version of tidy that is best for a task at hand.

Tidying the Cereals Data
| shelf | calories | protein | fat | sodium | fiber | carbo | sugars | potass | vitamins |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 102.5000 | 2.650000 | 0.60 | 176.2500 | 1.6850000 | 15.80000 | 4.800000 | 75.50000 | 20.00000 |
| 2 | 109.5238 | 1.904762 | 1.00 | 145.7143 | 0.9047619 | 13.61905 | 9.619048 | 57.80952 | 23.80952 |
| 3 | 107.7778 | 2.861111 | 1.25 | 158.6111 | 3.1388889 | 14.50000 | 6.527778 | 129.83333 | 35.41667 |
Code
my_colors <- c("calories_col" = "steelblue", "sugars_col" = "orange3")
cereal_wide |>
ggplot() +
geom_point(mapping = aes(x = shelf, y = calories, color = "calories_col")) +
geom_line(mapping = aes(x = shelf, y = calories, color = "calories_col")) +
geom_point(mapping = aes(x = shelf, y = sugars, color = "sugars_col")) +
geom_line(mapping = aes(x = shelf, y = sugars, color = "sugars_col")) +
scale_color_manual(values = my_colors, labels = names(my_colors)) +
labs(x = "Shelf", y = "", subtitle = "Mean Amount", color = "Nutrient")
| shelf | Nutrient | mean_amount |
|---|---|---|
| 1 | calories | 102.5000000 |
| 1 | carbo | 15.8000000 |
| 1 | fat | 0.6000000 |
| 1 | fiber | 1.6850000 |
| 1 | potass | 75.5000000 |
| 1 | protein | 2.6500000 |
| 1 | sodium | 176.2500000 |
| 1 | sugars | 4.8000000 |
| 1 | vitamins | 20.0000000 |
| 2 | calories | 109.5238095 |
| 2 | carbo | 13.6190476 |
| 2 | fat | 1.0000000 |
| 2 | fiber | 0.9047619 |
| 2 | potass | 57.8095238 |
| 2 | protein | 1.9047619 |
| 2 | sodium | 145.7142857 |
| 2 | sugars | 9.6190476 |
| 2 | vitamins | 23.8095238 |
| 3 | calories | 107.7777778 |
| 3 | carbo | 14.5000000 |
| 3 | fat | 1.2500000 |
| 3 | fiber | 3.1388889 |
| 3 | potass | 129.8333333 |
| 3 | protein | 2.8611111 |
| 3 | sodium | 158.6111111 |
| 3 | sugars | 6.5277778 |
| 3 | vitamins | 35.4166667 |

Pivoting Data


Manual Method
Consider daily rainfall observed in SLO in January 2023.
- The data is in a human-friendly form (like a calendar).
- Each week has a row, and each day has a column.

How would you manually convert this to long format?
Manual Method: Steps
- Keep the column
Week. - Create a new column
Day_of_Week. - Create a new column
Rainfall(hold daily rainfall values). - Now we have three columns – move Sunday values over.

Manual Method: Steps
- Keep the column
Week. - Create a new column
Day_of_Week. - Create a new column
Rainfall(hold daily rainfall values). - Now we have three columns – move Sunday values over.
- Duplicate
Week1-5 and copy Monday values over.

Computational Approach

We can use pivot_longer() to turn a wide dataset into a long(er) dataset.
Relational Data
Multiple, interconnected tables of data are called relational.
- It is the relation between datasets, not just the individual datasets themselves, that are important.

IMDb movie relational data
Keys
A key uniquely identifies an observation in a data set.
- To combine (join) two datasets, the key needs to be present in both.

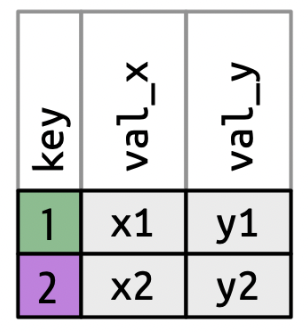
inner_join()
Keeps observations when their keys are present in both datasets.
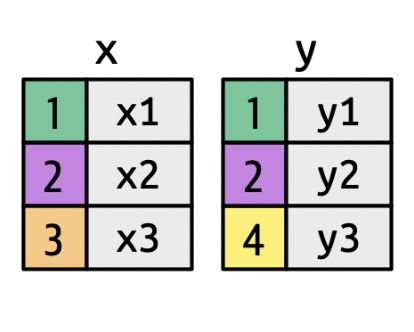
More Mutating Joins
left_join()– keep only (and all) observations present in the left data setright_join()– keep only (and all) observations present in the right data setfull_join()– keep only (and all) observations present in both data sets
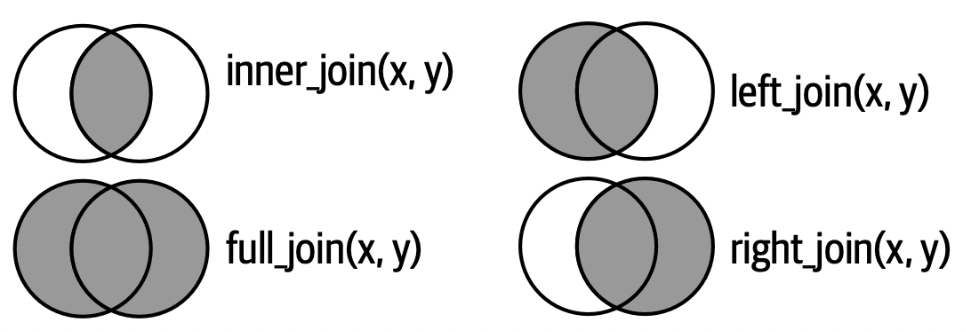
Filtering Joins: semi_join()
Keeps observations when their keys are present in both datasets, but only keeps variables from the first dataset.

→

Filtering Joins: anti_join()
Removes observations when their keys are present in both datasets, and only keeps variables from the first dataset.
→

dplyr Resources
Every group should have a dplyr cheatsheet!
On the Back: The Combine Tables section gives advice on joining two datasets
- The “Filtering Join” section will be helpful when performing an
anti_join()!

tidyr Resources
Every group should have a tidyr cheatsheet!
On the Front: The Reshape Data section gives advice on pivoting a dataset from wide to long