is_100m = df_bolt["Event"] == "2008 Olympics 100m"
df_100m = df_bolt[is_100m]
one_mean = df_100m["Time"].mean()
one_std = df_100m["Time"].std()
df_bolt["Standardized_Time"] = 0.0
df_bolt.loc[is_100m, "Standardized_Time"] = (df_bolt.loc[is_100m, "Time"] - Distances Between Observations
How does house size relate to number of bedrooms?
Code
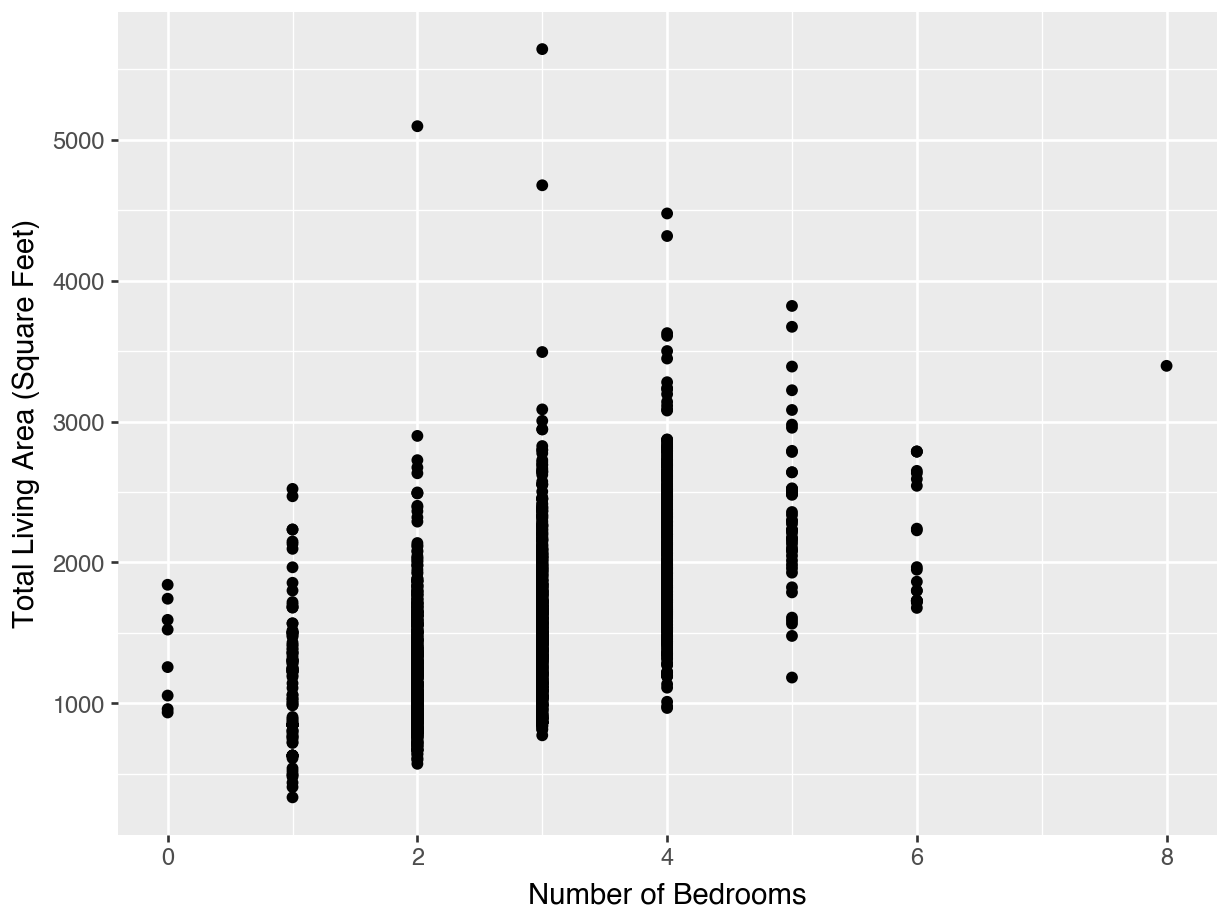
(
ggplot(housing, mapping = aes(x = "Gr Liv Area", y = "Bedroom AbvGr")) +
geom_point() +
labs(x = "Total Living Area",
y = "Number of Bedrooms") +
theme_bw()
)
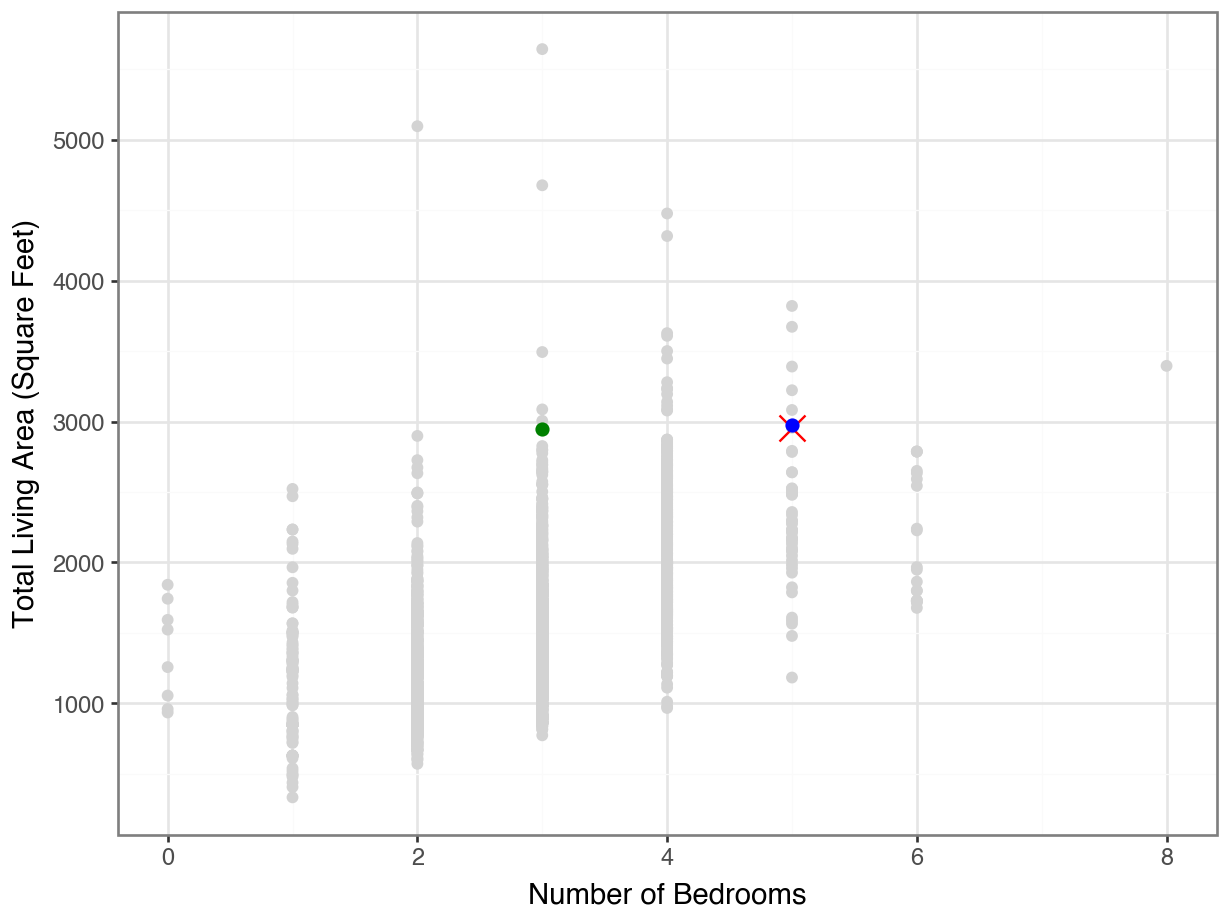
House 160 seems more similar to 1707…
Code
(
ggplot(housing, mapping = aes(y = "Gr Liv Area", x = "Bedroom AbvGr")) +
geom_point(color = "lightgrey") +
geom_point(housing.loc[[1707]], color = "orange", size = 5, shape = "x") +
geom_point(housing.loc[[160]], color = "blue", size = 2) +
geom_point(housing.loc[[2336]], color = "green", size = 2) +
theme_bw() +
labs(y = "Total Living Area (Square Feet)",
x = "Number of Bedrooms")
)
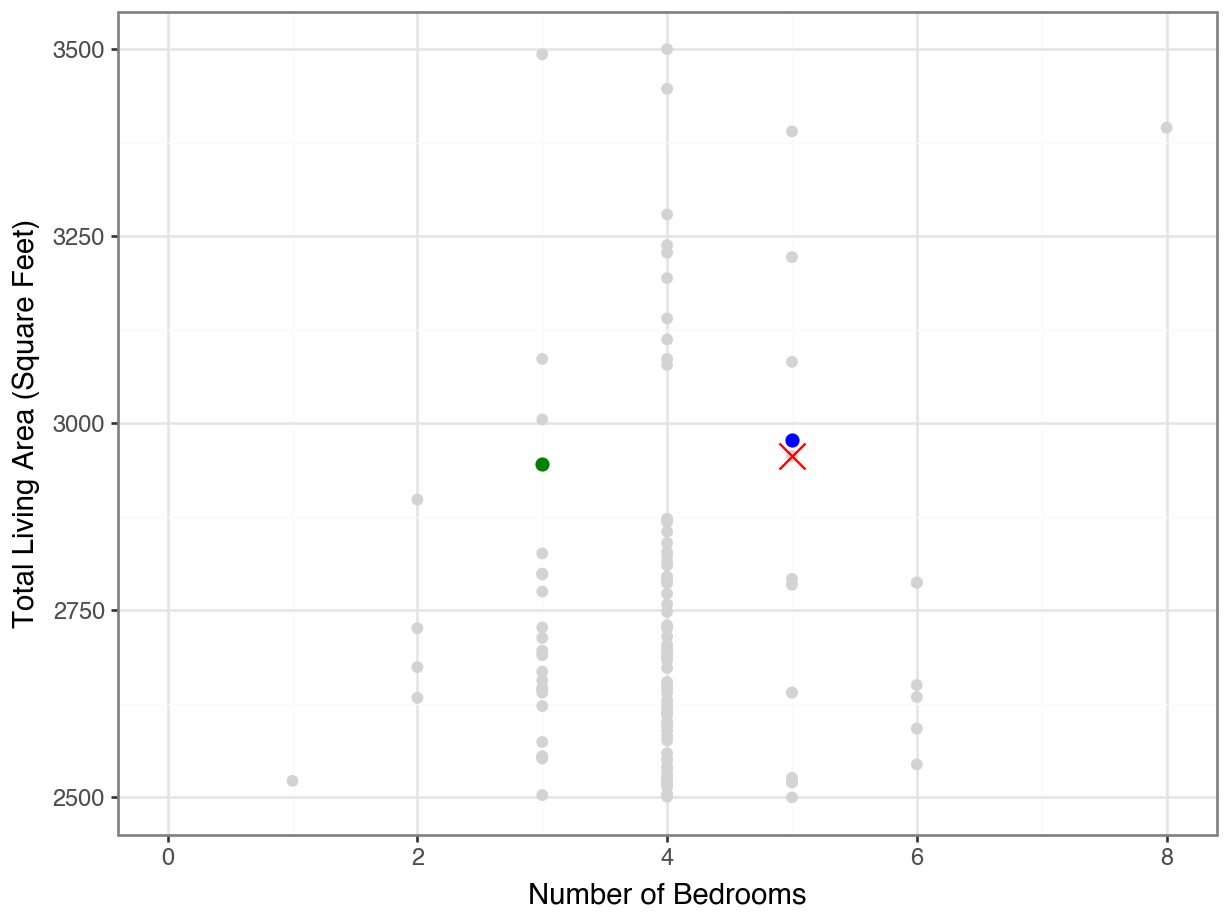
…even if we zoom in…
Code
(
ggplot(housing, mapping = aes(y = "Gr Liv Area", x = "Bedroom AbvGr")) +
geom_point(color = "lightgrey") +
geom_point(housing.loc[[1707]], color = "orange", size = 5, shape = "x") +
geom_point(housing.loc[[160]], color = "blue", size = 2) +
geom_point(housing.loc[[2336]], color = "green", size = 2) +
theme_bw() +
labs(y = "Total Living Area (Square Feet)",
x = "Number of Bedrooms") +
scale_y_continuous(limits = (2500, 3500))
)
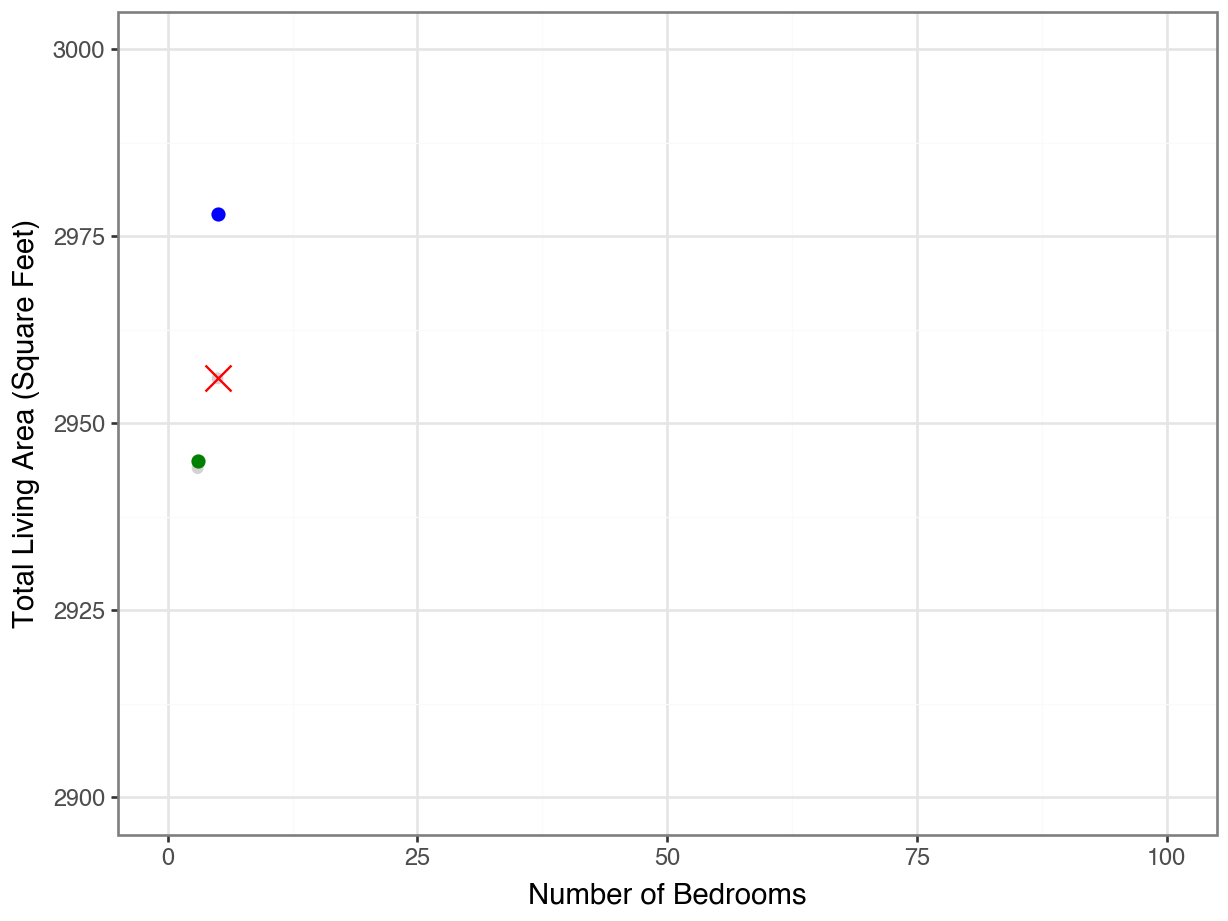
…but not if we put the axes on the same scale!
Code
(
ggplot(housing, aes(y = "Gr Liv Area", x = "Bedroom AbvGr")) +
geom_point(color = "lightgrey") +
geom_point(housing.loc[[1707]], color = "orange", size = 5, shape = "x") +
geom_point(housing.loc[[160]], color = "blue", size = 2) +
geom_point(housing.loc[[2336]], color = "green", size = 2) +
theme_bw() +
labs(y = "Total Living Area (Square Feet)",
x = "Number of Bedrooms") +
scale_y_continuous(limits = (2900, 3000)) +
scale_x_continuous(limits = (0, 100))
)
Scaling
housing['size_scaled'] = (housing['Gr Liv Area'] - housing['Gr Liv Area'].mean()) / housing['Gr Liv Area'].std()
housing['bdrm_scaled'] = (housing['Bedroom AbvGr'] - housing['Bedroom AbvGr'].mean()) / housing['Bedroom AbvGr'].std()Code
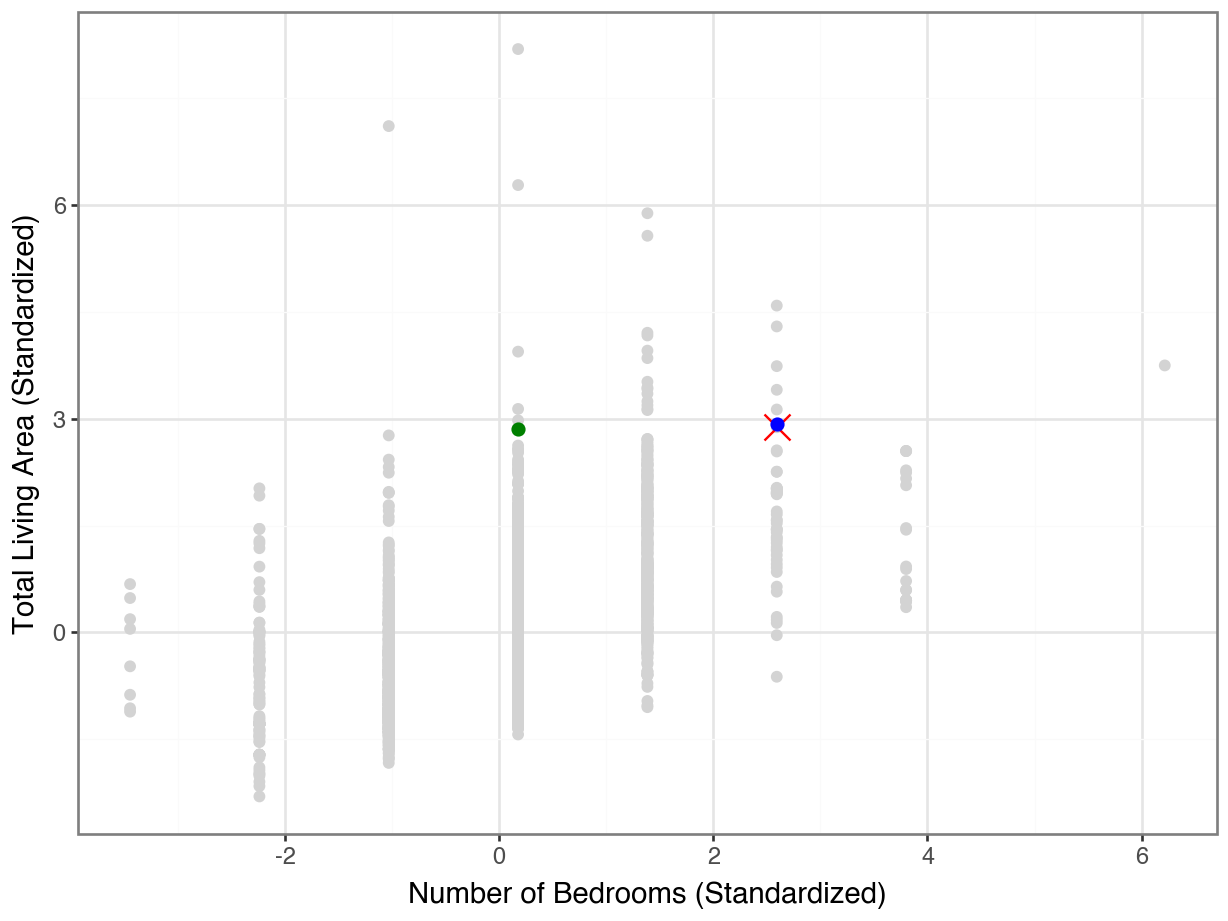
(
ggplot(housing, aes(y = "size_scaled", x = "bdrm_scaled")) +
geom_point(color = "lightgrey") +
geom_point(housing.loc[[1707]], color = "orange", size = 5, shape = "x") +
geom_point(housing.loc[[160]], color = "blue", size = 2) +
geom_point(housing.loc[[2336]], color = "green", size = 2) +
theme_bw() +
labs(y = "Total Living Area (Standardized)",
x = "Number of Bedrooms (Standardized)")
)